Publications ordered by year in reverse chronological order.Order by: type
2024
Multi-Task Adaptive Gating Network for Trajectory Distilled Control Prediction
Shoaib Azam, and Ville Kyrki
IEEE Robotics and Automation Letters, 2024
End-to-end autonomous driving is often categorized based on output into trajectory prediction or control prediction. Each type of approach provides benefits in different contexts, resulting in recent studies on how to combine them. However, the current proposals are based on heuristic choices that only partially capture the complexities of varying driving conditions. How to best fuse these sources of information remains an open research question. To address this, we introduce MAGNet, a Multi-Task Adaptive Gating Network for Trajectory Distilled Control Prediction. This framework employs a multi-task learning strategy to combine trajectory and direct control prediction. Our key insight is to design a gating network that learns how to optimally combine the outputs of trajectory and control predictions in each situation. Using the CARLA simulator, we evaluate MAGNet in closed-loop settings with challenging scenarios. Results show that MAGNet outperforms the state-of-the-art on two publicly available CARLA benchmarks, Town05 Long and Longest6.
@article{azam2024multi,show_bib={true},title={Multi-Task Adaptive Gating Network for Trajectory Distilled Control Prediction},author={Azam, Shoaib and Kyrki, Ville},journal={IEEE Robotics and Automation Letters},year={2024},publisher={IEEE}}
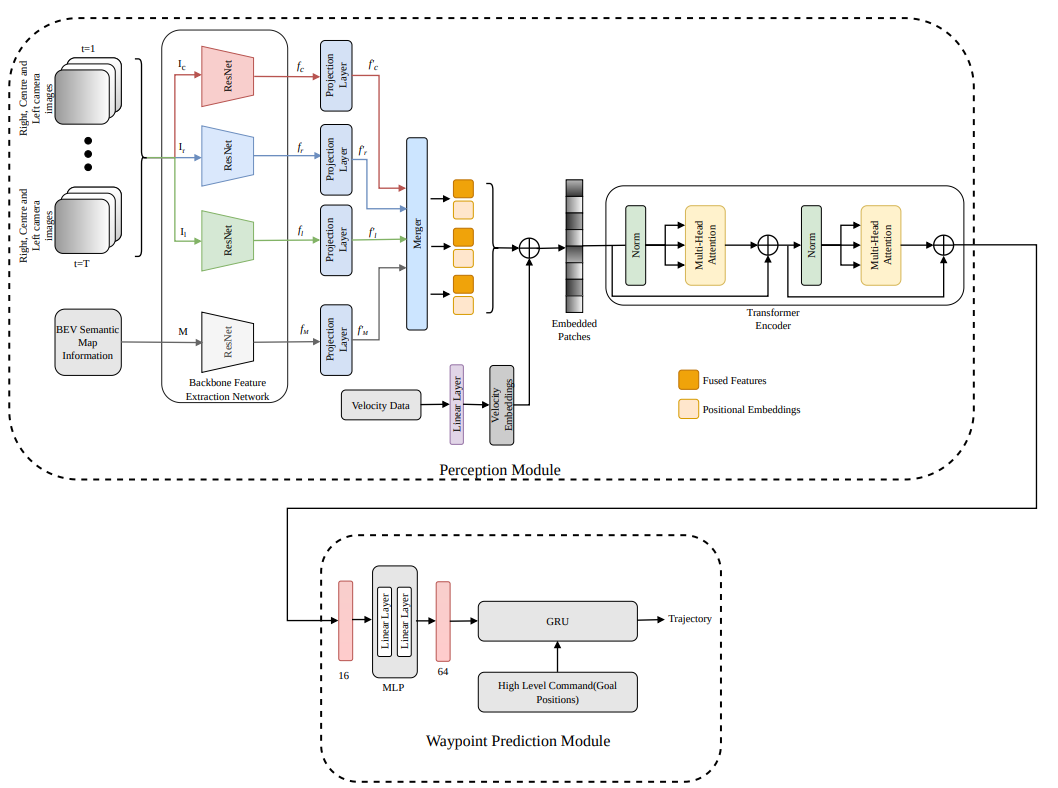
Exploring Contextual Representation and Multi-Modality for End-to-End Autonomous Driving
arXiv preprint arXiv:2210.06758, 2024
Learning contextual and spatial environmental representations enhances autonomous vehicle’s hazard anticipation and decision-making in complex scenarios. Recent perception systems enhance spatial understanding with sensor
fusion but often lack full environmental context. Humans, when driving, naturally employ neural maps that integrate various factors such as historical
data, situational subtleties, and behavioral predictions of other road users
to form a rich contextual understanding of their surroundings. This neural
map-based comprehension is integral to making informed decisions on the
road. In contrast, even with their significant advancements, autonomous
systems have yet to fully harness this depth of human-like contextual understanding. Motivated by this, our work draws inspiration from human
driving patterns and seeks to formalize the sensor fusion approach within
an end-to-end autonomous driving framework. We introduce a framework
that integrates three cameras (left, right, and center) to emulate the human
field of view, coupled with top-down bird-eye-view semantic data to enhance
contextual representation. The sensor data is fused and encoded using a
self-attention mechanism, leading to an auto-regressive waypoint prediction
module. We treat feature representation as a sequential problem, employing a vision transformer to distill the contextual interplay between sensor
modalities. The efficacy of the proposed method is experimentally evaluated
in both open and closed-loop settings. Our method achieves displacement
error by 0.67m in open-loop settings, surpassing current methods by 6.9%
on the nuScenes dataset. In closed-loop evaluations on CARLA’s Town05
Long and Longest6 benchmarks, the proposed method enhances driving performance, route completion, and reduces infractions.
@article{azamexploring,show_bib={true},title={Exploring Contextual Representation and Multi-Modality for End-to-End Autonomous Driving},author={},journal={arXiv preprint arXiv:2210.06758},year={2024}}
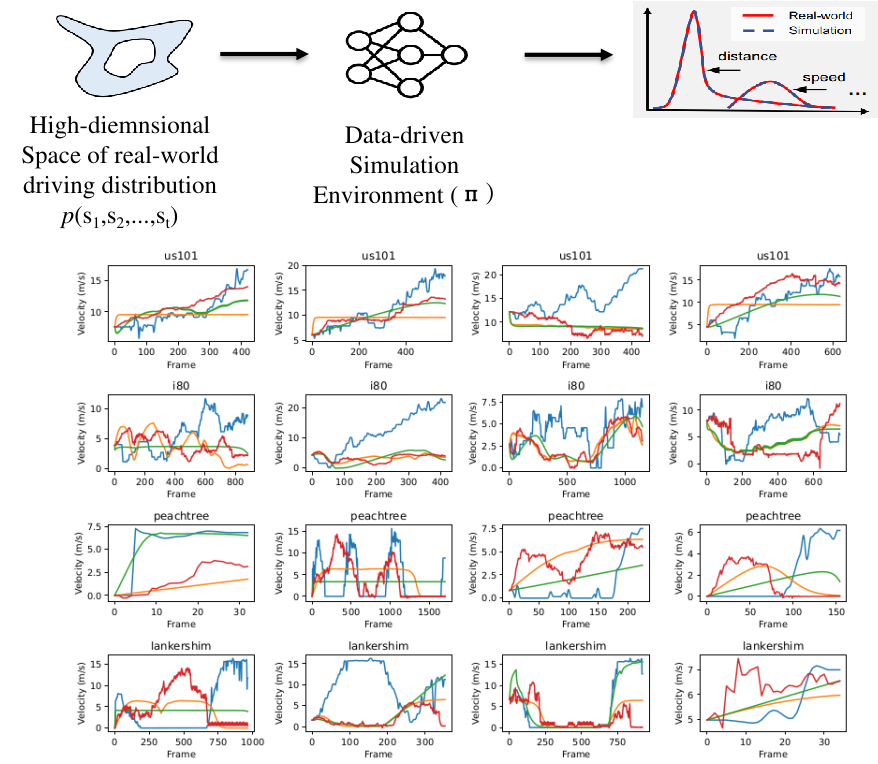
Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors
Kalle Kujanpää, Daulet Baimukashev, Shibei Zhu, Shoaib Azam, Farzeen Munir, Gokhan Alcan, and Ville Kyrki
In , 2024
Building simulation environments for developing and testing autonomous vehicles necessitates that the simulators accurately model the statistical realism of the real-world environment, including the interaction with other vehicles driven by human drivers. To address this requirement, an accurate human behavior model is essential to incorporate the diversity and consistency of human driving behavior. We propose a mathematical framework for designing a data-driven simulation model that simulates human driving behavior more realistically than the currently used physics-based simulation models. Experiments conducted using the NGSIM dataset validate our hypothesis regarding the necessity of considering the complexity, diversity, and consistency of human driving behavior when aiming to develop realistic simulators.
@inproceedings{kujanpaa2024challenges,show_bib={true},title={Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors},author={Kujanp{\"a}{\"a}, Kalle and Baimukashev, Daulet and Zhu, Shibei and Azam, Shoaib and Munir, Farzeen and Alcan, Gokhan and Kyrki, Ville},journal={arXiv preprint arXiv:2401.03236},year={2024}}
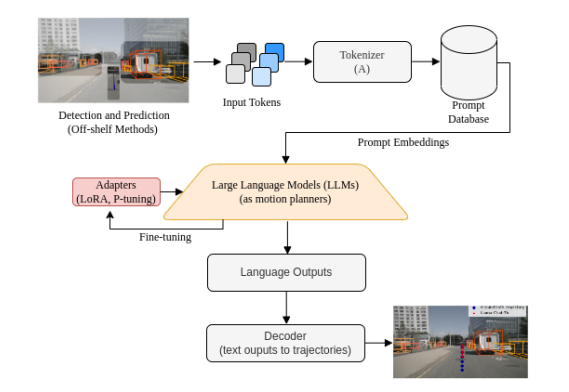
Exploring Large Language Models for Trajectory Prediction: A Technical Perspective
Farzeen Munir, Tsvetomila Mihaylova, Shoaib Azam, Tomasz Piotr Kucner, and Ville Kyrki
In Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, 2024
Large Language Models (LLMs) have been recently proposed for trajectory prediction in autonomous driving, where they potentially can provide explainable reasoning capability about driving situations. Most studies use versions of the OpenAI GPT, while there are open-source alternatives which have not been evaluated in this context. In this report1, we study their trajectory prediction performance as well as their ability to reason about the situation. Our results indicate that open-source alternatives are feasible for trajectory prediction. However, their ability to describe situations and reason about potential consequences of actions appears limited, and warrants future research.
@inproceedings{10.1145/3610978.3640625,show_bib={true},author={Munir, Farzeen and Mihaylova, Tsvetomila and Azam, Shoaib and Kucner, Tomasz Piotr and Kyrki, Ville},title={Exploring Large Language Models for Trajectory Prediction: A Technical Perspective},year={2024},isbn={9798400703232},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3610978.3640625},doi={10.1145/3610978.3640625},booktitle={Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction},pages={774–778},numpages={5},keywords={autonomous driving, large language models, trajectory prediction},location={<conf-loc>, <city>Boulder</city>, <state>CO</state>, <country>USA</country>, </conf-loc>},series={HRI '24}}
2023
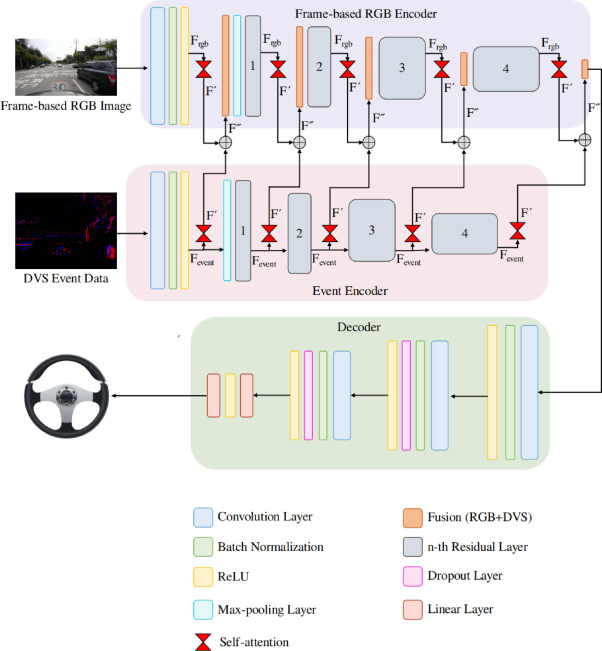
Multimodal fusion for sensorimotor control in steering angle prediction
Engineering Applications of Artificial Intelligence, 2023
Imitation learning is employed to learn sensorimotor coordination for steering angle prediction in an end-to-end fashion requires expert demonstrations. These expert demonstrations are paired with environmental perception and vehicle control data. The conventional frame-based RGB camera is the most common exteroceptive sensor modality used to acquire the environmental perception data. The frame-based RGB camera has produced promising results when used as a single modality in learning end-to-end lateral control. However, the conventional frame-based RGB camera has limited operability in illumination variation conditions and is affected by the motion blur. The event camera provides complementary information to the frame-based RGB camera. This work explores the fusion of frame-based RGB and event data for learning end-to-end lateral control by predicting steering angle. In addition, how the representation from event data fuse with frame-based RGB data helps to predict the lateral control robustly for the autonomous vehicle. To this end, we propose DRFuser, a novel convolutional encoder-decoder architecture for learning end-to-end lateral control. The encoder module is branched between the frame-based RGB data and event data along with the self-attention layers. Moreover, this study has also contributed to our own collected dataset comprised of event, frame-based RGB, and vehicle control data. The efficacy of the proposed method is experimentally evaluated on our collected dataset, Davis Driving dataset (DDD), and Carla Eventscape dataset. The experimental results illustrate that the proposed method DRFuser outperforms the state-of-the-art in terms of root-mean-square error (RMSE) and mean absolute error (MAE) used as evaluation metrics.
@article{munir2023multimodal,show_bib={true},title={Multimodal fusion for sensorimotor control in steering angle prediction},author={Munir, Farzeen and Azam, Shoaib and Yow, Kin-Choong and Lee, Byung-Geun and Jeon, Moongu},journal={Engineering Applications of Artificial Intelligence},volume={126},pages={107087},year={2023},publisher={Elsevier}}
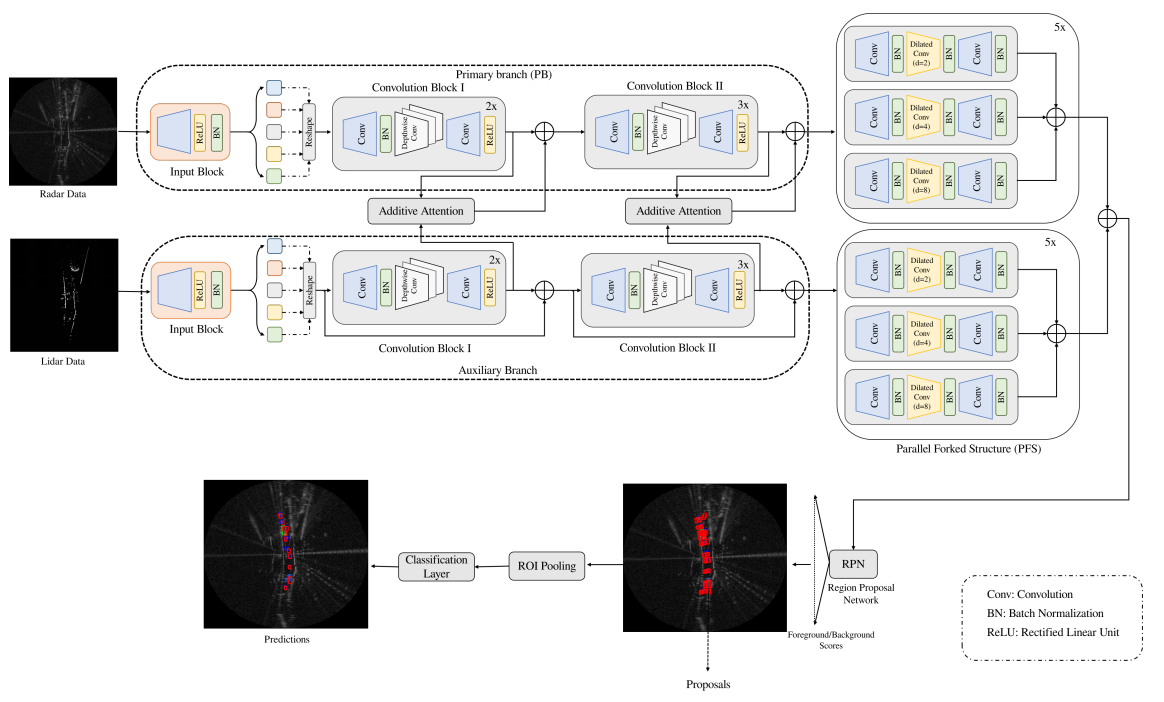
Radar-Lidar Fusion for Object Detection by Designing Effective Convolution Networks
Farzeen Munir, Shoaib Azam, Tomasz Kucner, Ville Kyrkil, and Moongu Jeon
In 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), 2023
Object detection is a core component of perception systems, providing the ego vehicle with information about its surroundings to ensure safe route planning. While cameras and Lidar have significantly advanced perception systems, their performance can be limited in adverse weather conditions. In contrast, millimeter-wave technology enables radars to function effectively in such conditions. However, relying solely on radar for building a perception system doesn’t fully capture the environment due to the data’s sparse nature. To address this, sensor fusion strategies have been introduced. We propose a dual-branch framework to integrate radar and Lidar data for enhanced object detection. The primary branch focuses on extracting radar features, while the auxiliary branch extracts Lidar features. These are then combined using additive attention. Subsequently, the integrated features are processed through a novel Parallel Forked Structure (PFS) to manage scale variations. A region proposal head is then utilized for object detection. We evaluated the effectiveness of our proposed method on the Radiate dataset using COCO metrics. The results show that it surpasses state-of-the-art methods by 1.89% and 2.61% in favorable and adverse weather conditions, respectively. This underscores the value of radar-Lidar fusion in achieving precise object detection and localization, especially in challenging weather conditions.
@inproceedings{munir2023radar,show_bib={true},title={Radar-Lidar Fusion for Object Detection by Designing Effective Convolution Networks},author={Munir, Farzeen and Azam, Shoaib and Kucner, Tomasz and Kyrkil, Ville and Jeon, Moongu},booktitle={2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC)},pages={3575--3582},year={2023},organization={IEEE}}
2022
Exploring thermal images for object detection in underexposure regions for autonomous driving
Farzeen Munir, Shoaib Azam, Muhammd Aasim Rafique, Ahmad Muqeem Sheri, Moongu Jeon, and Witold Pedrycz
Applied Soft Computing, 2022
Underexposure regions are vital in constructing a complete perception of the surrounding environment for safe autonomous driving. The availability of thermal cameras has provided an essential alternative to explore regions where other optical sensors lack in capturing interpretable signals. A thermal camera captures an image using the heat difference emitted by objects in the infrared spectrum, and object detection in thermal images becomes effective for autonomous driving in challenging conditions. Although object detection in the visible spectrum domain has matured, thermal object detection lacks effectiveness. A significant challenge is the scarcity of labeled data for the thermal domain, which is essential for SOTA artificial intelligence techniques. This work proposes a domain adaptation framework that employs a style transfer technique for transfer learning from visible spectrum images to thermal images. The framework uses a generative adversarial network (GAN) to transfer the low-level features from the visible spectrum domain to the thermal domain through style consistency. The efficacy of the proposed object detection method in thermal images is evident from the improved results when using styled images from publicly available thermal image datasets (FLIR ADAS and KAIST Multi-Spectral).
@article{munir2022exploring,show_bib={true},title={Exploring thermal images for object detection in underexposure regions for autonomous driving},author={Munir, Farzeen and Azam, Shoaib and Rafique, Muhammd Aasim and Sheri, Ahmad Muqeem and Jeon, Moongu and Pedrycz, Witold},journal={Applied Soft Computing},volume={121},pages={108793},year={2022},publisher={Elsevier}}
Drivable region estimation for self-driving vehicles using radar
Muhammad Ishfaq Hussain, Shoaib Azam, Muhammad Aasim Rafique, Ahmad Muqeem Sheri, and Moongu Jeon
IEEE Transactions on Vehicular Technology, 2022
Self-driving vehicles are posing new challenges as the automation level defined in the SAE International standards for autonomous driving is increased. A pivotal task in autonomous driving is building a perception of the surrounding environment using optical sensors, which is a long-standing challenge and prompts us to explore the utilization of various sensors. Radar is an older and cheaper type of sensor than alternatives such as lidar for long-range distance coverage, and it is also competitively reliable and robust in adverse weather conditions. However, sparse data and noise are inherent challenges of radar. This study explores the dynamic Gaussian process for occupancy mapping and predicting a drivable path for a self-driving vehicle within the field of view (FOV) of a radar sensor. Gaussian occupancy mapping does not need abundant data for training and is a promising alternative to data-reliant deep learning techniques. The proposed technique optimizes parameters (variational and kernel-based) of the Gaussian process to determine the allowed region within the FOV limits by means of stochastic selection of functional points (pseudoinput) and tuning of threshold values. We have tested the proposed technique in experiments performed under different environmental conditions, such as various road and traffic conditions and diverse weather and illumination conditions. The results verify the efficacy of the proposed technique in diverse weather conditions for finding a drivable path for a self-driving vehicle, with the additional benefits of requiring only a low-cost apparatus and providing coverage of a long distance range.
@article{hussain2022drivable,show_bib={true},title={Drivable region estimation for self-driving vehicles using radar},author={Hussain, Muhammad Ishfaq and Azam, Shoaib and Rafique, Muhammad Aasim and Sheri, Ahmad Muqeem and Jeon, Moongu},journal={IEEE Transactions on Vehicular Technology},volume={71},number={6},pages={5971--5982},year={2022},publisher={IEEE}}
2021
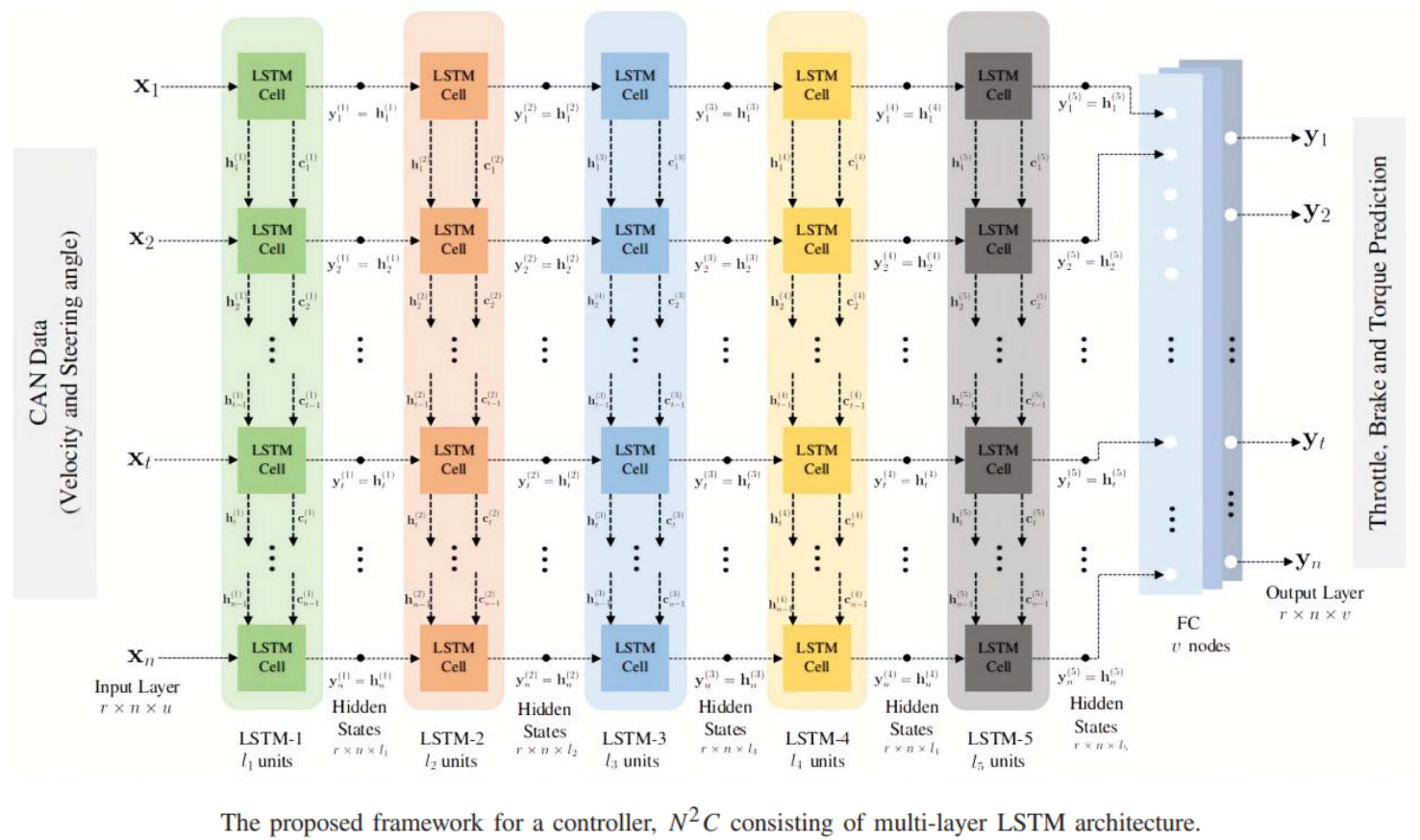
N 2 C: neural network controller design using behavioral cloning
Shoaib Azam, Farzeen Munir, Muhammad Aasim Rafique, Ahmad Muqeem Sheri, Muhammad Ishfaq Hussain, and Moongu Jeon
IEEE Transactions on Intelligent Transportation Systems, 2021
Modern vehicles communicate data to and from sensors, actuators, and electronic control units (ECUs) using Controller Area Network (CAN) bus, which operates on differential signaling. An autonomous ECU responsible for the execution of decision commands to an autonomous vehicle is developed by assimilating the information from the CAN bus. The conventional way of parsing the decision commands is motion planning, which uses a path tracking algorithm to evaluate the decision commands. This study focuses on designing a robust controller using behavioral cloning and motion planning of autonomous vehicle using a deep learning framework. In the first part of this study, we explore the pipeline of parsing decision commands from the path tracking algorithm to the controller and proposed a neural network-based controller ( N 2 C) using behavioral cloning. The proposed network predicts throttle, brake, and torque when trained with the manual driving data acquired from the CAN bus. The efficacy of the proposed method is demonstrated by comparing the accuracy with the Proportional-Derivative-Integral (PID) controller in conjunction with the path tracking algorithm (pure pursuit and model predictive control based path follower). The second part of this study complements N 2 C, in which an end-to-end neural network for predicting the speed and steering angle is proposed with image data as an input. The performance of the proposed frameworks are evaluated in real-time and on the Udacity dataset, showing better metric scores in the former and reliable prediction in the later case when compared with the state-of-the-art methods.
@article{azam2021n,show_bib={true},title={N 2 C: neural network controller design using behavioral cloning},author={Azam, Shoaib and Munir, Farzeen and Rafique, Muhammad Aasim and Sheri, Ahmad Muqeem and Hussain, Muhammad Ishfaq and Jeon, Moongu},journal={IEEE Transactions on Intelligent Transportation Systems},volume={22},number={7},pages={4744--4756},year={2021},publisher={IEEE}}
Channel boosting feature ensemble for radar-based object detection
Shoaib Azam, Farzeen Munir, and Moongu Jeon
In 2021 IEEE Intelligent Vehicles Symposium (IV), 2021
Autonomous vehicles are conceived to provide safe and secure services by validating the safety standards as indicated by SOTIF-ISO/PAS-21448 (Safety of the intended functionality). Keeping in this context, the perception of the environment plays an instrumental role in conjunction with localization, planning and control modules. As a pivotal algorithm in the perception stack, object detection provides extensive insights into the autonomous vehicle’s surroundings. Camera and Lidar are extensively utilized for object detection among different sensor modalities, but these exteroceptive sensors have limitations in resolution and adverse weather conditions. In this work, radar-based object detection is explored provides a counterpart sensor modality to be deployed and used in adverse weather conditions. The radar gives complex data; for this purpose, a channel boosting feature ensemble method with transformer encoder-decoder network is proposed. The object detection task using radar is formulated as a set prediction problem and evaluated on the publicly available dataset [1] in both good and good-bad weather conditions. The proposed method’s efficacy is extensively evaluated using the COCO evaluation metric, and the best-proposed model surpasses its state-of-the-art counterpart method by 12.55% and 12.48% in both good and good-bad weather conditions.
@inproceedings{azam2021channel,show_bib={true},title={Channel boosting feature ensemble for radar-based object detection},author={Azam, Shoaib and Munir, Farzeen and Jeon, Moongu},booktitle={2021 IEEE Intelligent Vehicles Symposium (IV)},pages={762--769},year={2021},organization={IEEE}}
Sstn: Self-supervised domain adaptation thermal object detection for autonomous driving
Farzeen Munir, Shoaib Azam, and Moongu Jeon
In 2021 IEEE/RSJ international conference on intelligent robots and systems (IROS), 2021
The perception of the environment plays a decisive role in the safe and secure operation of autonomous vehicles. The perception of the surrounding is way similar to human vision. The human’s brain perceives the environment by utilizing different sensory channels and develop a view-invariant representation model. In this context, different exteroceptive sensors like cameras, Lidar, are deployed on the autonomous vehicle to perceive the environment. These sensors have illustrated their benefit in the visible spectrum domain yet in the adverse weather conditions; for instance, they have limited operational capability at night, leading to fatal accidents. This work explores thermal object detection to model a view-invariant model representation by employing the self-supervised contrastive learning approach. We have proposed a deep neural network Self Supervised Thermal Network (SSTN) for learning the feature embedding to maximize the information between visible and infrared spectrum domain by contrastive learning. Later, these learned feature representations are employed for thermal object detection using a multi-scale encoder-decoder transformer network. The proposed method is extensively evaluated on the two publicly available datasets: the FLIR-ADAS dataset and the KAIST Multi-Spectral dataset. The experimental results illustrate the efficacy of the proposed method.
@inproceedings{munir2021sstn,show_bib={true},title={Sstn: Self-supervised domain adaptation thermal object detection for autonomous driving},author={Munir, Farzeen and Azam, Shoaib and Jeon, Moongu},booktitle={2021 IEEE/RSJ international conference on intelligent robots and systems (IROS)},pages={206--213},year={2021},organization={IEEE}}
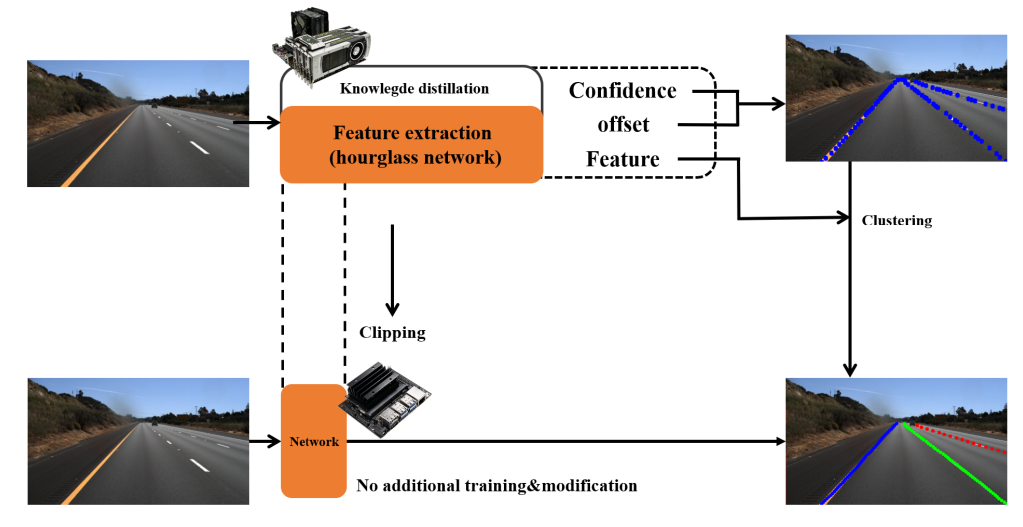
Key points estimation and point instance segmentation approach for lane detection
IEEE Transactions on Intelligent Transportation Systems, 2021
Perception techniques for autonomous driving should be adaptive to various environments. In essential perception modules for traffic line detection, many conditions should be considered, such as a number of traffic lines and computing power of the target system. To address these problems, in this paper, we propose a traffic line detection method called Point Instance Network (PINet); the method is based on the key points estimation and instance segmentation approach. The PINet includes several hourglass models that are trained simultaneously with the same loss function. Therefore, the size of the trained models can be chosen according to the target environment’s computing power. We cast a clustering problem of the predicted key points as an instance segmentation problem; the PINet can be trained regardless of the number of the traffic lines. The PINet achieves competitive accuracy and false positive on CULane and TuSimple datasets, popular public datasets for lane detection. Our code is available at https://github.com/koyeongmin/PINet_new
@article{ko2021key,show_bib={true},title={Key points estimation and point instance segmentation approach for lane detection},author={Ko, Yeongmin and Lee, Younkwan and Azam, Shoaib and Munir, Farzeen and Jeon, Moongu and Pedrycz, Witold},journal={IEEE Transactions on Intelligent Transportation Systems},volume={23},number={7},pages={8949--8958},year={2021},publisher={IEEE}}
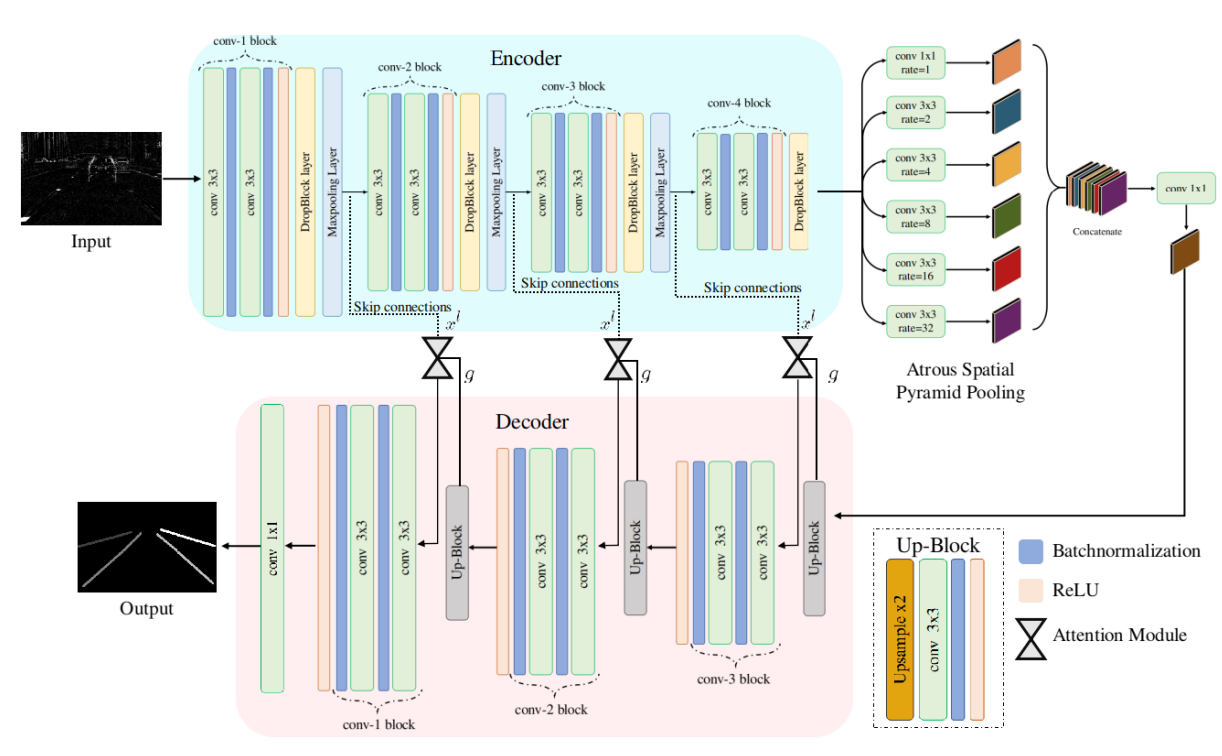
LDNet: End-to-end lane marking detection approach using a dynamic vision sensor
IEEE Transactions on Intelligent Transportation Systems, 2021
Modern vehicles are equipped with various driver-assistance systems, including automatic lane keeping, which prevents unintended lane departures. Traditional lane detection methods incorporate handcrafted or deep learning-based features followed by postprocessing techniques for lane extraction using frame-based RGB cameras. The utilization of frame-based RGB cameras for lane detection tasks is prone to illumination variations, sun glare, and motion blur, which limits the performance of lane detection methods. Incorporating an event camera for lane detection tasks in the perception stack of autonomous driving is one of the most promising solutions for mitigating challenges encountered by frame-based RGB cameras. The main contribution of this work is the design of the lane marking detection model, which employs the dynamic vision sensor. This paper explores the novel application of lane marking detection using an event camera by designing a convolutional encoder followed by the attention-guided decoder. The spatial resolution of the encoded features is retained by a dense atrous spatial pyramid pooling (ASPP) block. The additive attention mechanism in the decoder improves performance for high dimensional input encoded features that promote lane localization and relieve postprocessing computation. The efficacy of the proposed work is evaluated using the DVS dataset for lane extraction (DET). The experimental results show a significant improvement of 5.54% and 5.03% in F1 scores in multiclass and binary-class lane marking detection tasks. Additionally, the intersection over union ( IoU ) scores of the proposed method surpass those of the best-performing state-of-the-art method by 6.50% and 9.37% in multiclass and binary-class tasks, respectively.
@article{munir2021ldnet,show_bib={true},title={LDNet: End-to-end lane marking detection approach using a dynamic vision sensor},author={Munir, Farzeen and Azam, Shoaib and Jeon, Moongu and Lee, Byung-Geun and Pedrycz, Witold},journal={IEEE Transactions on Intelligent Transportation Systems},volume={23},number={7},pages={9318--9334},year={2021},publisher={IEEE}}
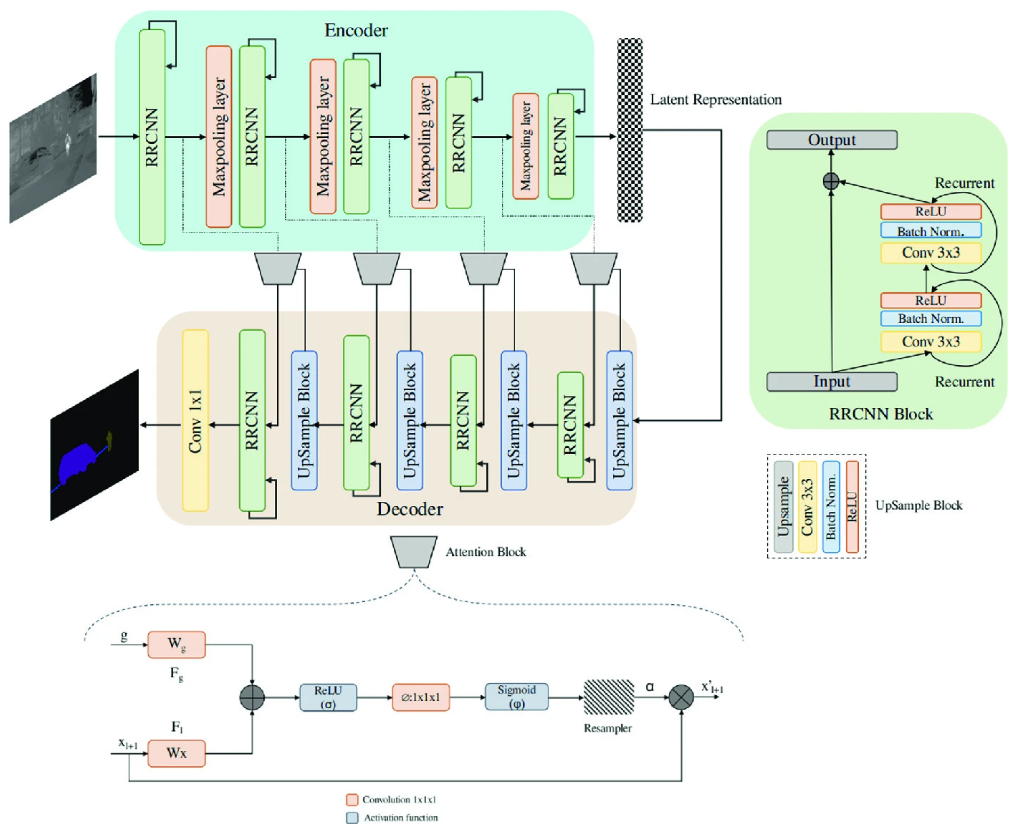
ARTSEG: Employing attention for thermal images semantic segmentation
Farzeen Munir, Shoaib Azam, Unse Fatima, and Moongu Jeon
In Asian Conference on Pattern Recognition, 2021
The research advancements have made the neural network algorithms deployed in the autonomous vehicle to perceive the surrounding. The standard exteroceptive sensors that are utilized for the perception of the environment are cameras and Lidar. Therefore, the neural network algorithms developed using these exteroceptive sensors have provided the necessary solution for the autonomous vehicle’s perception. One major drawback of these exteroceptive sensors is their operability in adverse weather conditions, for instance, low illumination and night conditions. The useability and affordability of thermal cameras in the sensor suite of the autonomous vehicle provide the necessary improvement in the autonomous vehicle’s perception in adverse weather conditions. The semantics of the environment benefits the robust perception, which can be achieved by segmenting different objects in the scene. In this work, we have employed the thermal camera for semantic segmentation. We have designed an attention-based Recurrent Convolution Network (RCNN) encoder-decoder architecture named ARTSeg for thermal semantic segmentation. The main contribution of this work is the design of encoder-decoder architecture, which employ units of RCNN for each encoder and decoder block. Furthermore, additive attention is employed in the decoder module to retain high-resolution features and improve the localization of features. The efficacy of the proposed method is evaluated on the available public dataset, showing better performance with other state-of-the-art methods in mean intersection over union (IoU).
@inproceedings{munir2021artseg,show_bib={true},title={ARTSEG: Employing attention for thermal images semantic segmentation},author={Munir, Farzeen and Azam, Shoaib and Fatima, Unse and Jeon, Moongu},booktitle={Asian Conference on Pattern Recognition},pages={366--378},year={2021},organization={Springer International Publishing Cham}}
2020
Transfer learning for vehicle detection using two cameras with different focal lengths
This paper proposes a vehicle detection method using transfer learning for two cameras with different focal lengths. A detected vehicle region in an image of one camera is transformed into a binary map. After that, the map is used to filter convolutional neural network (CNN) feature maps which are computed for the other camera’s image. We also introduce a robust evolutionary algorithm that is used to compute the relationship between the two cameras in an off-line mode efficiently. We capture video sequences and sample them to make a dataset that includes images with different focal lengths for vehicle detection. We compare the proposed vehicle detection method with baseline detection methods, including faster region proposal networks (Faster-RCNN), single-shot-multi-Box detector (SSD), and detector using recurrent rolling convolution (RRC), in the same experimental context. The experimental results show that the proposed method can detect vehicles at a wide range of distances accurately and robustly, and significantly outperforms the baseline detection methods.
@article{dinh2020transfer,show_bib={true},title={Transfer learning for vehicle detection using two cameras with different focal lengths},author={Dinh, Vinh Quang and Munir, Farzeen and Azam, Shoaib and Yow, Kin-Choong and Jeon, Moongu},journal={Information Sciences},volume={514},pages={71--87},year={2020},publisher={Elsevier}}
Dynamic Control System Design for Autonomous Car
Shoaib Azam, Farzeen Munir, and Moongu Jeon
In VEHITS, 2020
The autonomous vehicle requires higher standards of safety to maneuver in a complex environment. We focus on control of the self-driving vehicle that includes the longitudinal and lateral dynamics of the vehicle. In this work, we have developed a customized controller for our KIA Soul self-driving car. The customized controller implements the PID control for throttle, brake, and steering so that the vehicle follows the desired velocity profile, which enables a comfortable and safe ride. Besides, we have also catered the lateral dynamic model with two approaches: pure pursuit and model predictive control. An extensive analysis is performed between pure pursuit and its adversary model predictive control for the efficacy of the lateral model.
@inproceedings{azam2020dynamic,show_bib={true},title={Dynamic Control System Design for Autonomous Car},author={Azam, Shoaib and Munir, Farzeen and Jeon, Moongu},booktitle={VEHITS},pages={456--463},year={2020}}
Multiple objects tracking using radar for autonomous driving
Muhamamd Ishfaq Hussain, Shoaib Azam, Farzeen Munir, Zafran Khan, and Moongu Jeon
In 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), 2020
Object detection and tracking are the integral elements for the perception of the spatio-temporal environment. The availability and affordability of camera and lidar as the leading sensor modalities have used for object detection and tracking in research. The usage of deep learning algorithms for the object detection and tracking using camera and lidar have illustrated the promising results, but these sensor modalities are prone to weather conditions, have sparse data and spatial resolution problems. In this work, we explore the problem of detecting distant objects and tracking using radar. For the efficacy of our proposed work, extensive experimentation in different traffic scenario are performed by using our self-driving car test-bed.
@inproceedings{hussain2020multiple,show_bib={true},title={Multiple objects tracking using radar for autonomous driving},author={Hussain, Muhamamd Ishfaq and Azam, Shoaib and Munir, Farzeen and Khan, Zafran and Jeon, Moongu},booktitle={2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS)},pages={1--4},year={2020},organization={IEEE}}
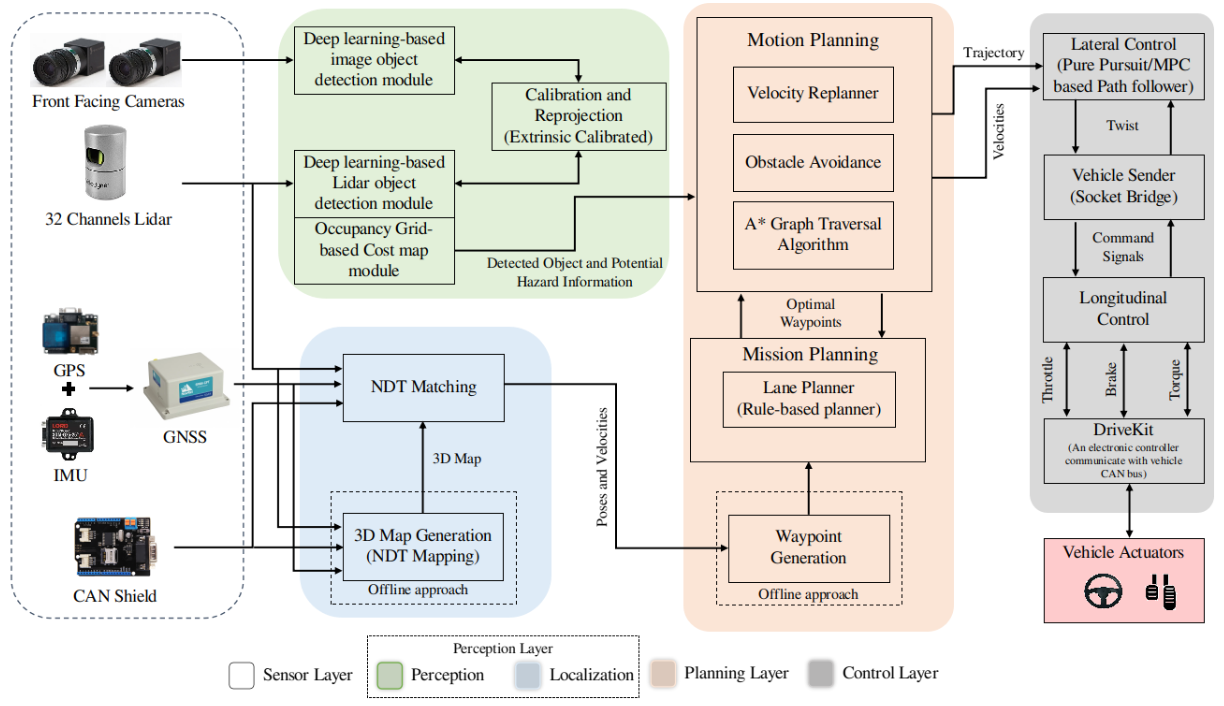
System, design and experimental validation of autonomous vehicle in an unconstrained environment
Shoaib Azam, Farzeen Munir, Ahmad Muqeem Sheri, Joonmo Kim, and Moongu Jeon
Sensors, 2020
In recent years, technological advancements have made a promising impact on the development of autonomous vehicles. The evolution of electric vehicles, development of state-of-the-art sensors, and advances in artificial intelligence have provided necessary tools for the academia and industry to develop the prototypes of autonomous vehicles that enhance the road safety and traffic efficiency. The increase in the deployment of sensors for the autonomous vehicle, make it less cost-effective to be utilized by the consumer. This work focuses on the development of full-stack autonomous vehicle using the limited amount of sensors suite. The architecture aspect of the autonomous vehicle is categorized into four layers that include sensor layer, perception layer, planning layer and control layer. In the sensor layer, the integration of exteroceptive and proprioceptive sensors on the autonomous vehicle are presented. The perception of the environment in term localization and detection using exteroceptive sensors are included in the perception layer. In the planning layer, algorithms for mission and motion planning are illustrated by incorporating the route information, velocity replanning and obstacle avoidance. The control layer constitutes lateral and longitudinal control for the autonomous vehicle. For the verification of the proposed system, the autonomous vehicle is tested in an unconstrained environment. The experimentation results show the efficacy of each module, including localization, object detection, mission and motion planning, obstacle avoidance, velocity replanning, lateral and longitudinal control. Further, in order to demonstrate the experimental validation and the application aspect of the autonomous vehicle, the proposed system is tested as an autonomous taxi service.
@article{azam2020system,show_bib={true},title={System, design and experimental validation of autonomous vehicle in an unconstrained environment},author={Azam, Shoaib and Munir, Farzeen and Sheri, Ahmad Muqeem and Kim, Joonmo and Jeon, Moongu},journal={Sensors},volume={20},number={21},pages={5999},year={2020},publisher={MDPI}}
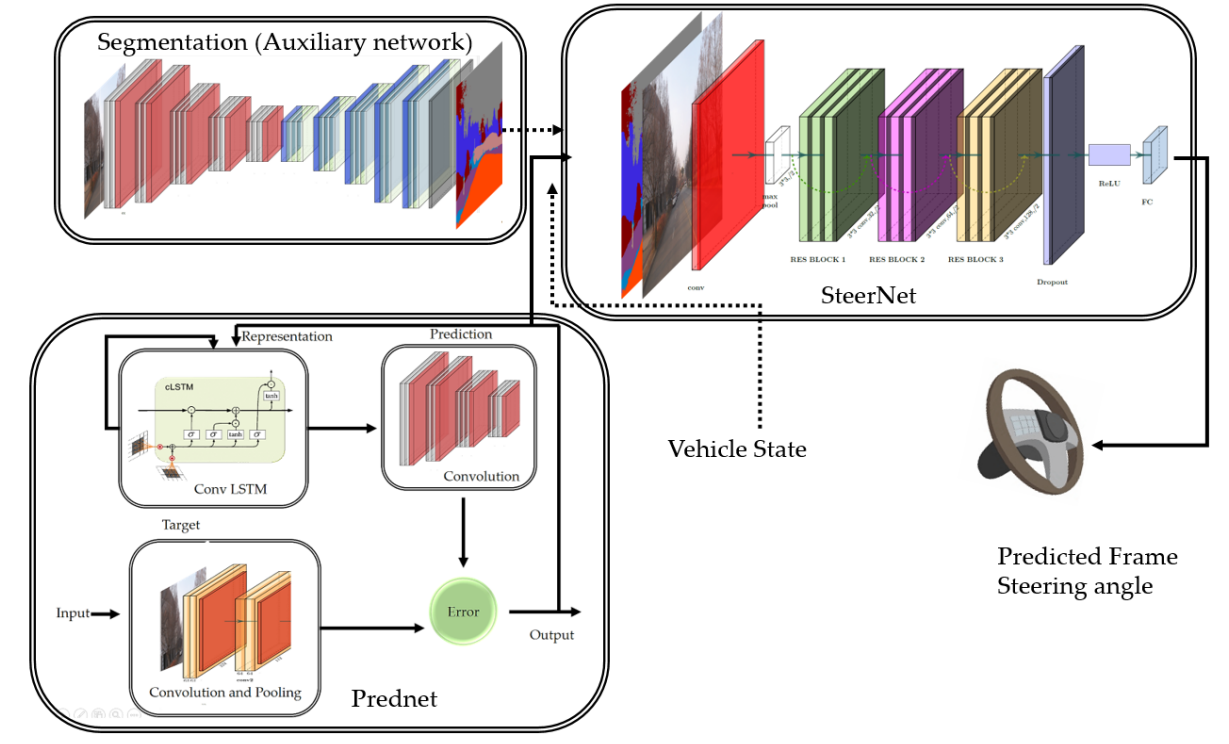
Visuomotor Steering angle Prediction in Dynamic Perception Environment for Autonomous Vehicle
Farzeen Munir, Shoaib Azam, and Moongu Jeon
In 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), 2020
Visuomotor coordination in driving assists the driver in performing necessary action expeditiously. Over the recent years, the development towards autonomous vehicles has accelerated tremendously, and an increase in the computational capabilities motivates us to train the complex deep neural network models using visual cues for better understanding of visuomotor coordination in the autonomous vehicles. In this work, we exploit this problem by using visual cues in the images to predict the steering angle for a self-driving car. The future frames are predicted to estimate a look-ahead steering angle so that self-driving car can make appropriate decisions. In our dynamic predictive model, we have used the deep convolution-LSTM model for predicting the future frames and a series of ResNet blocks for predicting the steering angle for the self-driving car. Moreover, we have used segmentation as an auxiliary information for training the dynamic predictive network. The efficacy of our dynamic predictive model is rigorously tested on our collected and Udacity dataset.
@inproceedings{munir2020visuomotor,show_bib={true},title={Visuomotor Steering angle Prediction in Dynamic Perception Environment for Autonomous Vehicle},author={Munir, Farzeen and Azam, Shoaib and Jeon, Moongu},booktitle={2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia)},pages={1--6},year={2020},organization={IEEE}}
2019
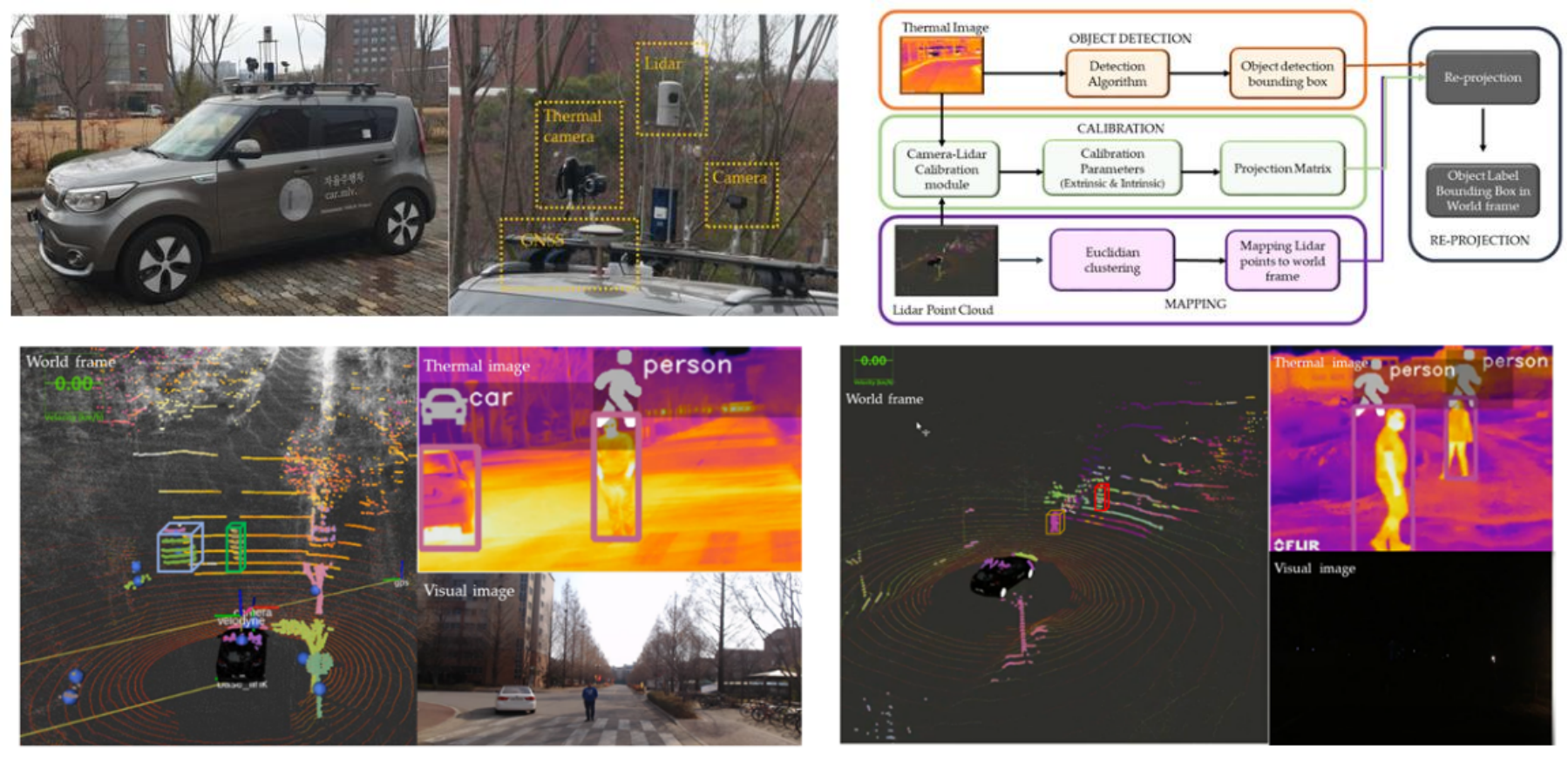
Data fusion of lidar and thermal camera for autonomous driving
Shoaib Azam, Farzeen Munir, Ahmad Muqeem Sheri, YeongMin Ko, Ishfaq Hussain, and Moongu Jeon
In Applied Industrial Optics: Spectroscopy, Imaging and Metrology, 2019
The adverse environmental conditions build a bottleneck for the autonomous driving. This challenge is resolved by data fusion of sensor modalities. Here, thermal and Lidar data are fused together for the precise perception of environment.
@inproceedings{azam2019data,show_bib={true},title={Data fusion of lidar and thermal camera for autonomous driving},author={Azam, Shoaib and Munir, Farzeen and Sheri, Ahmad Muqeem and Ko, YeongMin and Hussain, Ishfaq and Jeon, Moongu},booktitle={Applied Industrial Optics: Spectroscopy, Imaging and Metrology},pages={T2A--5},year={2019},organization={Optica Publishing Group}}
Automated Taxi Booking Operations for Autonomous Vehicles
Linh Van Ma, Shoaib Azam, Farzeen Munir, Moongu Jeon, and Jinho Choi
In 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), 2019
In a conventional taxi booking system, all taxi operations are mostly done by a decision made by drivers which is hard to implement in unmanned vehicles. To address this challenge, we introduce a taxi booking system which assists autonomous vehicles to pick up customers. The system can allocate an autonomous vehicle (AV) as well as plan service trips for a customer request. We use our own AV to serve a customer who uses a mobile application to make his taxi request. Apart from customer and AV, we build a server to monitor customers and AVs. It also supports inter-communication between a customer and an AV once AV decided to pick up a customer.
@inproceedings{van2019automated,show_bib={true},title={Automated Taxi Booking Operations for Autonomous Vehicles},author={Van Ma, Linh and Azam, Shoaib and Munir, Farzeen and Jeon, Moongu and Choi, Jinho},booktitle={2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS)},pages={1--5},year={2019},organization={IEEE}}
Where Am I: Localization and 3D Maps for Autonomous Vehicles
Farzeen Munir, Shoaib Azam, Ahmad Muqeem Sheri, YeongMin Ko, and Moongu Jeon
In VEHITS, 2019
The nuts and bolts of autonomous driving find its root in devising the localization strategy. Lidar as one of the newest technologies developed in the recent years, provides rich information about the environment in the form of point cloud data which can be used for localization. In this paper, we discuss a localization approach which generates a 3D map from Lidar’s point cloud data using Normal Distribution Transform (NDT) mapping. We use our own dataset collected using our self driving car KIA Soul EV equipped with Lidar and cameras. Once the 3D map has been generated, we have used NDT matching for localizing the self driving car.
@inproceedings{munir2019localization,show_bib={true},title={Where Am I: Localization and 3D Maps for Autonomous Vehicles},author={Munir, Farzeen and Azam, Shoaib and Sheri, Ahmad Muqeem and Ko, YeongMin and Jeon, Moongu},booktitle={VEHITS},volume={2019},pages={452--457},year={2019}}
2018
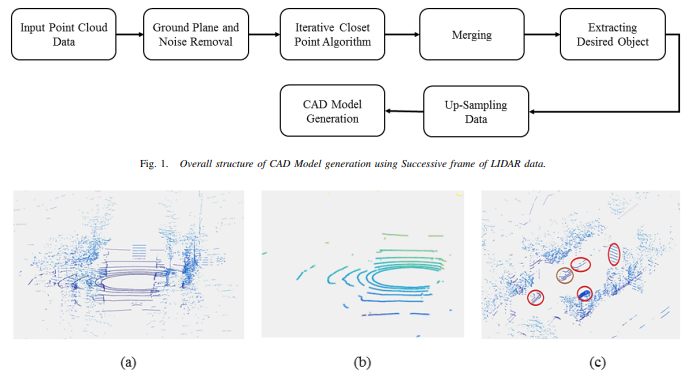
Object modeling from 3d point cloud data for self-driving vehicles
Shoaib Azam, Farzeen Munir, Aasim Rafique, YeongMin Ko, Ahmad Muqeem Sheri, and Moongu Jeon
In 2018 IEEE Intelligent Vehicles Symposium (IV), 2018
For autonomous vehicles to be deployed and used practically, many problems are still needed to be solved. One of them we are interested in is to make use of a cheap LIDAR for robust object modelling with 3D point cloud data. Self-driving vehicles require accurate information about the surrounding environments to decide the next course of actions. 3D point cloud data obtained from LIDAR give more accurate distance than the counterpart stereo images. As LIDAR generates lowresolution data, the object detection and modeling is prone to produce errors. In this work, we propose the use of multiple frames of LIDAR data in an urban environment to construct a comprehensive model of the object. We assume the use of LIDAR on a moving platform and the results are almost equal to the 3D CAD model representation of the object.
@inproceedings{azam2018object,show_bib={true},title={Object modeling from 3d point cloud data for self-driving vehicles},author={Azam, Shoaib and Munir, Farzeen and Rafique, Aasim and Ko, YeongMin and Sheri, Ahmad Muqeem and Jeon, Moongu},booktitle={2018 IEEE Intelligent Vehicles Symposium (IV)},pages={409--414},year={2018},organization={IEEE}}
Autonomous vehicle: The architecture aspect of self driving car
Farzeen Munir, Shoaib Azam, Muhammad Ishfaq Hussain, Ahmed Muqeem Sheri, and Moongu Jeon
In Proceedings of the 2018 International Conference on Sensors, Signal and Image Processing, 2018
Self-driving cars have received a lot of attention in recent years and many stakeholders like Google, Uber, Tesla, and so forth have invested a lot in this area and developed their own autonomous driving car platforms. The challenge to make an autonomous car is not only the stringent performance but also the safety of the passengers and pedestrians. Even with the development of technologies, autonomous driving is still an active research area and still requires a lot of experimentations and making architecture entirely autonomous.
The intriguing area of self-driving car motivates us to build an autonomous driving platform. In this paper, we discuss the architecture of the self-driving car and its software components that include localization, detection, motion planning and mission planning. We also highlight the hardware modules that are responsible for controlling the car. The autonomous driving is running state-of-the-art algorithms used in localization, detection, mission and motion planning.
@inproceedings{munir2018autonomous,show_bib={true},title={Autonomous vehicle: The architecture aspect of self driving car},author={Munir, Farzeen and Azam, Shoaib and Hussain, Muhammad Ishfaq and Sheri, Ahmed Muqeem and Jeon, Moongu},booktitle={Proceedings of the 2018 International Conference on Sensors, Signal and Image Processing},pages={1--5},year={2018}}
2017
Face de-identification method (translated), Registration #: 10-1861520
Muhammad Aasim Rafique, Shoaib Azam, InMoon Choi, and Moongu Jeon
2017
@misc{rafique2017,show_bib={true},title={Face de-identification method (translated), Registration #: 10-1861520},author={Rafique, Muhammad Aasim and Azam, Shoaib and Choi, InMoon and Jeon, Moongu},year={2017}}
2016
A Benchmark of Computational Models of Saliency to Predict Human Fixations in Videos.
Shoaib Azam, Syed Omer Gilani, Moongu Jeon, Rehan Yousaf, and Jeong-Bae Kim
In VISIGRAPP (4: VISAPP), 2016
In many applications of computer graphics and design, robotics and computer vision, there is always a need
to predict where human looks in the scene. However this is still a challenging task that how human visual
system certainly works. A number of computational models have been designed using different approaches
to estimate the human visual system. Most of these models have been tested on images and performance is
calculated on this basis. A benchmark is made using images to see the immediate comparison between the
models. Apart from that there is no benchmark on videos, to alleviate this problem we have a created a
benchmark of six computational models implemented on 12 videos which have been viewed by 15 observers
in a free viewing task. Further a weighted theory (both manual and automatic) is designed and implemented
on videos using these six models which improved Area under the ROC. We have found that Graph Based
Visual Saliency (GBVS) and Random Centre Surround Models have outperformed the other models.
@inproceedings{azam2016benchmark,show_bib={true},title={A Benchmark of Computational Models of Saliency to Predict Human Fixations in Videos.},author={Azam, Shoaib and Gilani, Syed Omer and Jeon, Moongu and Yousaf, Rehan and Kim, Jeong-Bae},booktitle={VISIGRAPP (4: VISAPP)},pages={134--142},year={2016}}
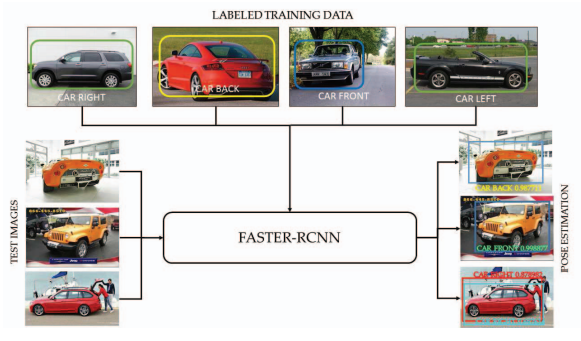
Vehicle pose detection using region based convolutional neural network
Shoaib Azam, Aasim Rafique, and Moongu Jeon
In 2016 International Conference on Control, Automation and Information Sciences (ICCAIS), 2016
In recent years, category-level object detection has gained a lot of attention. In addition to object localization, estimation of the object pose has practical applications in intelligent transportation, autonomous driving and robotics. Parts based models have been used for pose estimation in recent years, but these models depend on manual supervision or require a complex algorithm to locate the object parts. In this work, we have used Convolutional Neural Network for the pose estimation of vehicle in an image. The advantage of multiple classifications of objects at the same time motivates us to choose the convolutional neural network. We make use of state-of-the-art implementation of convolution neural network named the Region Based Convolutional Neural Network(FASTER-RCNN) for estimating the pose of vehicle. We annotate the comprehensive cars dataset of Stanford, required for training the model and upon testing we have achieved good results with good accuracy.
@inproceedings{azam2016vehicle,show_bib={true},title={Vehicle pose detection using region based convolutional neural network},author={Azam, Shoaib and Rafique, Aasim and Jeon, Moongu},booktitle={2016 International Conference on Control, Automation and Information Sciences (ICCAIS)},pages={194--198},year={2016},organization={IEEE}}
Face-deidentification in images using restricted boltzmann machines
M Aasim Rafique, M Shoaib Azam, Moongu Jeon, and Sangwook Lee
In 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST), 2016
In this work, we discuss utility of Restricted Boltzmann Machine (RBM) in face-deidentification challenge. GRBM is a generative modeling technique and its unsupervised learning provides vantage of using raw faces data. Faces are deidentified by reconstructed face images from the trained GRBM model. The reconstructed image uses random information from the stochastic units which makes it hard to re-identify from the deidentified face. Experiments show the proposed technique maintain emotions in the test face, which is intrinsic to the modeling capacity of RBM.
@inproceedings{rafique2016face,show_bib={true},title={Face-deidentification in images using restricted boltzmann machines},author={Rafique, M Aasim and Azam, M Shoaib and Jeon, Moongu and Lee, Sangwook},booktitle={2016 11th International Conference for Internet Technology and Secured Transactions (ICITST)},pages={69--73},year={2016},organization={IEEE}}
Single object tracking system using fast compressive tracking
Abdullah Tahir, Shoaib Azam, Sujani Sagabala, Moongu Jeon, and Ryu Jeha
In 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), 2016
In this work we focused on the application aspect of object tracking for pan-tilt-zoom (PTZ) camera using ordinary webcam mounted on custom made motor-assembly and found that our system is not only robust to illumination conditions but also cost-effective in comparison with PTZ cameras. For object tracking we utilized Fast Compressive Tracking (FCT) algorithm because of its attractive features e.g. online learning, fast computation and robust performance. A PC program interfaced with embedded system through serial RS232 commands motors, hence camera, to real time track desired object in world such that object being tracked remains in the center of image.
@inproceedings{tahir2016single,show_bib={true},title={Single object tracking system using fast compressive tracking},author={Tahir, Abdullah and Azam, Shoaib and Sagabala, Sujani and Jeon, Moongu and Jeha, Ryu},booktitle={2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia)},pages={1--3},year={2016},organization={IEEE}}
2015
Saliency Based Object Detection and Enhancements Using Spectral Residual Approach in Static Images and Videos
Muhammad Shoaib Azam, Syed Omer Gilani, Mohsin Jamil, Yasar Ayaz, Muhammad Naveed, and Muhammad Nasir Khan
Advanced Science Letters, 2015
Salient feature extraction in images and videos are of high concern from the aspect of object detection.
Today there are many techniques which are used to extract the salient features. Salient features are basically the
most attention taking features seen by the human eye. In the frequency domain the most appropriate method is the
spectral residual approach using the Phase Fourier Transform (PFT) which gives better result than other techniques.
In this paper we are implementing the spectral residual method using the Phase Fourier Transform to find out the
salient areas. These results have been immensely improved by applying edge detection techniques and
morphological operations. To make the object detectable sobel operator and dilation is used. After applying we get
better results and a very clean view of the salient areas and in some cases we almost prove total object detection.
Furthermore PFT is implemented on videos and for object detection sobel operator and dilation is applied on the
results given by PFT. Finally Area under the Receiver Operating Characteristics (AUC) is calculated for both
images and videos.
@article{azam2015saliency,show_bib={true},title={Saliency Based Object Detection and Enhancements Using Spectral Residual Approach in Static Images and Videos},author={Azam, Muhammad Shoaib and Gilani, Syed Omer and Jamil, Mohsin and Ayaz, Yasar and Naveed, Muhammad and Khan, Muhammad Nasir},journal={Advanced Science Letters},volume={21},number={12},pages={3677--3679},year={2015},publisher={American Scientific Publishers}}